Graphics Core Next
Graphics Core Next (グラフィックス コア ネクスト、GCN) とはAMDによって開発されたマイクロアーキテクチャのシリーズおよび命令セットの両方を指すコードネーム。GCNはAMDによって同社のGPU向けにTeraScaleマイクロアーキテクチャ命令セットの後継として開発された。最初のGCN搭載製品は2011年に発表された[1]。
GCNはAMD Radeon HD 7700-7900、HD 8000、RX 240-290、RX 300、RX 400、RX 500、Vegaシリーズに加えてRadeon VIIグラフィックスカードの28nm、14nm、7nmグラフィックスチップで使用されている。また、コードネーム"Temash"、"Kabini"、"Kaveri"、"Carrizo"、"Beema"および"Mullins"などのAMD Accelerated Processing Unit(APU)、またLiverpool (PlayStation 4) およびDurango (Xbox One) でも使われている。
GCNはTeraScaleのVLIW SIMDアーキテクチャとは対照的なRISC SIMDマイクロアーキテクチャである。GCNはTeraScaleよりもかなり多くのトランジスタを必要とするが、GPGPU演算において優位となる。GCNはHyperZを実装する[2]。
命令セット
編集GCN命令セットはx86-64命令セットと同様にAMDによって策定されている。GCN命令セットはGPUに特化して開発されており、除算などのマイクロ演算は持たない。
次の文書が公開されている。
- “Southern Islands Series Instruction Set Architecture” (PDF). AMD (2012年12月). 2016年11月18日閲覧。
- “Sea Islands Series Instruction Set Architecture” (PDF). AMD (2013年2月). 2016年11月18日閲覧。
- “Graphics Core Next Architecture, Generation 3” (PDF). AMD (2016年8月). 2016年11月18日閲覧。
GCN命令セット用のLLVMコードジェネレータ(バックエンドコンパイラ)が用意されている[3]。これは例えばMesa 3Dに使われている。
AMD Southern Islands GPGPU命令セット (Graphics Core Nextとも言う) のオープンソースRTL実装 "MIAOW"。
- “MIAOWWhitepaper : Hardware Description and Four Research Case Studies” (PDF). GitHub. 2016年11月18日閲覧。
2015年11月、AMDは "Boltzmann" 構想を発表した。AMD Boltzmann構想により、CUDAベースのアプリケーションを共通C++プログラミングモデルへ移植することが可能になるとされている[4]。
Super Computing 15にて、AMDはHeterogeneous Compute Compiler (HCC)、クラスタークラス用のヘッドレスLinuxドライバーおよびHSAランタイム基盤、High Performance Computing (HPC)、およびCUDAベースのアプリケーションを共通C++プログラミングモデルに移植するHeterogeneous-compute Interface for Portability (HIP) ツールを発表した。
マイクロアーキテクチャ
編集2016年1月時点で、命令セット "Graphics Core Next" と一貫して呼ばれるマイクロアーキテクチャのファミリーは3つのイテレーション(世代)があると見られる。命令セットの面においてはその違いはかなり小さく、マイクロアーキテクチャはお互いにあまり違いはない。
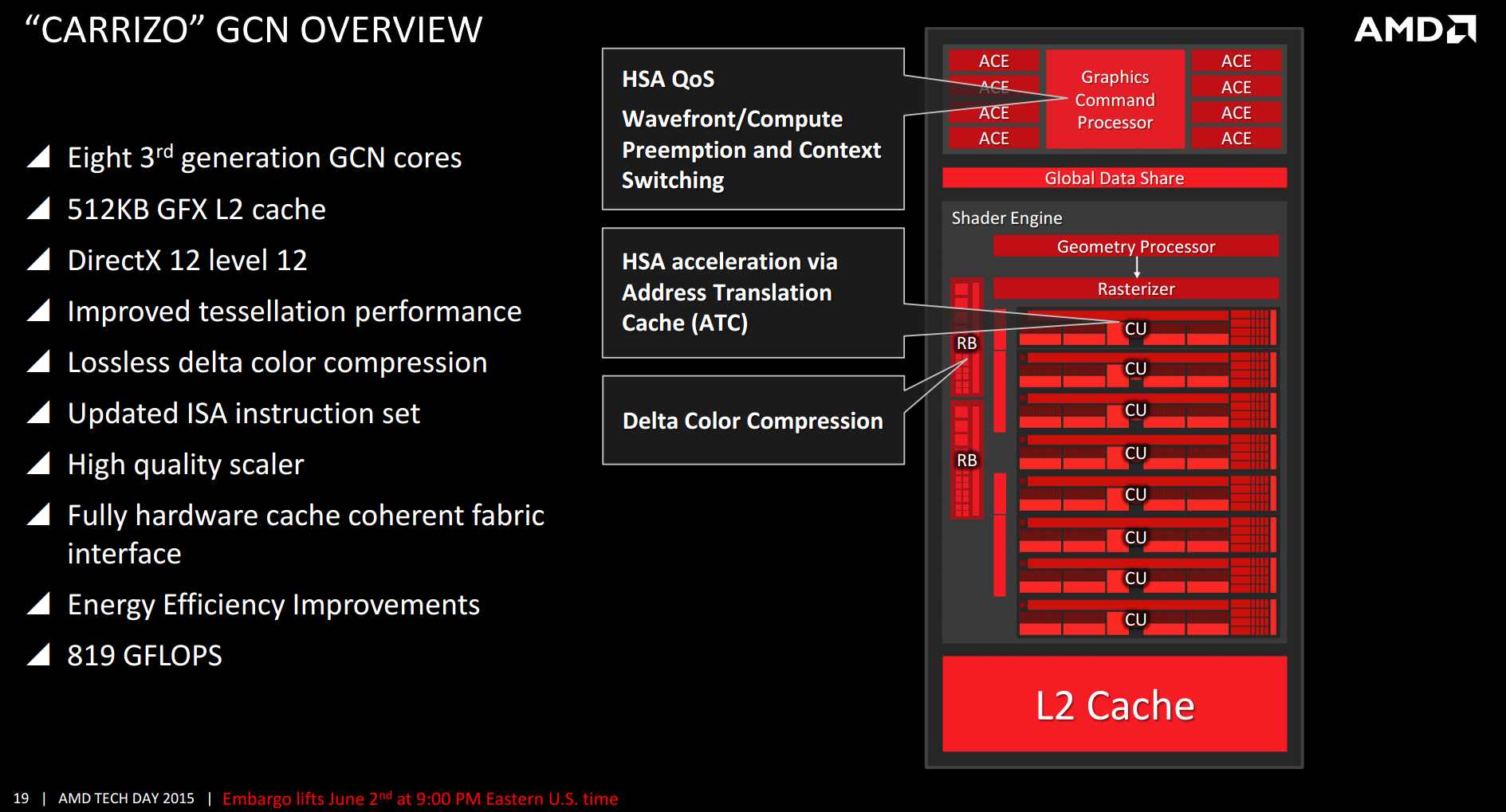
コマンド処理
編集
グラフィックスコマンドプロセッサ
編集グラフィックスコマンドプロセッサ (Graphics Command Processor) はGCNマイクロアーキテクチャの機能ユニットであり、いくつかあるタスクの中で特に、非同期シェーダーの役割を担っている。ショートビデオ「AMD Simplified: Asynchronous Shaders」[5][6]では、「マルチスレッド」「プリエンプション」「非同期シェーダー」の違いが視覚化されている。
- “Asynchronous Shaders White Paper” (PDF). AMD (2015年). 2016年11月18日閲覧。
- Ryan Smith (2015年3月31日). “AMD Dives Deep On Asynchronous Shading”. AnandTech. 2016年11月18日閲覧。
非同期コンピュートエンジン
編集非同期コンピュートエンジン (Asynchronous Compute Engine; ACE) は、演算目的に従事する明確な機能ブロックである。目的としては、グラフィックスコマンドプロセッサと似ている。
スケジューラ
編集GCNの第3世代より、ハードウェアは2基のスケジューラを搭載している。ひとつはシェーダー実行 (CUスケジューラ) 中のウェーブフロントのスケジュールを行ない、もうひとつの新しいスケジューラは描画キューとコンピュートキューの実行のスケジュールを行なう。後者は、固定機能パイプライン速度によって制限されるグラフィックスコマンドもしくは帯域幅のせいでCUの利用率が低いときにコンピュート演算を実行することで、パフォーマンスを向上する。この機能は非同期コンピュートとしても知られる。
与えられたシェーダーに対して、GPUドライバーは遅延を最小限にするため命令の実行順を適切に選択する必要がある。これはCPUによって行われ、またときおり「スケジューリング」と呼ばれることもある。
ジオメトリプロセッサ (Geometry Processor)
編集
ジオメトリプロセッサはジオメトリアセンブラ、テッセレータおよびバーテックスアセンブラを含んでいる。
ジオメトリプロセッサのGCNテッセレータはDirect3D 11およびOpenGL 4で定義されるようなハードウェアでのテッセレーションを実現する。
GCNテッセレータはAMDの最新のSIPブロックで、かつてのATI TruFormおよびTeraScaleのハードウェアテッセレーションにあたる。
コンピュートユニット (Compute Unit)
編集各コンピュートユニット (Compute Unit; CU) はCUスケジューラ、分岐およびメッセージユニット、4基のSIMDベクタユニット(それぞれ16レーン幅)、4つの64KiB VGPRファイル、1基のスカラユニット、4KiBのGPRファイル、64KiBのローカルデータ共有、4基のテクスチャフィルタユニット、16基のテクスチャフェッチロード・ストアユニットおよび16KiBのL1キャッシュで構成される。4基のコンピュートユニットは16KiB単位の命令キャッシュと32KiBのスカラデータキャッシュを共有する。これらはL2キャッシュによってバックアップされている。SUは一度に1個(サイクルあたり1回)演算するが、SIMD-VUは一度(サイクル毎)に16要素を演算する。さらに、SUはいくつかの他の演算を分岐のように扱うことができる。
いずれのSIMD-VUも各々でそのレジスタを記憶するメモリを持っている。それらには2種類のレジスタがある。4バイトの数字を保持するスカラレジスタ (s0, s1, etc) と、4バイト数値を64セット保持するベクタレジスタ (v0, v1, etc.) である。ベクタレジスタ上で演算するとき、どの演算も64個の数値で並列に行われる。つまり、それらで何かを処理をさせる度に64個を入力することができる。例えば、64個の異なるピクセルを一度に処理させることができる。(それぞれの入力はわずかに異なり、従って最終的にはわずかに異なる色を得られる。)
いずれのSIMD-VUも512個のスカラレジスタと256個のベクタレジスタを抱えている。
CUスケジューラ
編集CUスケジューラはSIMD-VUでどのウェーブフロントを実行させるかを選択するハードウェア機能的ブロックである。これはスケジューリングサイクル毎に1基のSIMD-VUを取り上げる。これはハードウェアまたはソフトウェアにおいて他のスケジューラと混同されることはない。
- ウェーブフロント (Wavefront)
- 「シェーダー」はグラフィックス処理を行なう小さなプログラムであり、また「カーネル」はGPGPU処理を行なう小さなプログラムである。前者は通例GLSL/HLSLで記述されるが、後者はOpenCL C言語もしくはGLSL/HLSL(コンピュートシェーダー)で記述できる。これらのプロセスはレジスタをあまり必要とせず、システムまたはグラフィックスメモリからのデータの読み込みを必要とする。この操作は大きく遅延が生じる。AMDとNVIDIAは複数のスレッドをグループ化するという方法でこの不可避な遅延を隠蔽するという、よく似たアプローチを選択している。AMDはこのグループをウェーブフロント、NVIDIAはワープと呼んでいる。スレッドのグループは遅延を隠蔽する仕組みを実装するGPUスケジューリングの最も基本的なユニットであり、SIMDスタイルで処理されるデータの最小サイズ、コードの最小実行可能ユニット、同時に全てのスレッドを単一の命令で処理する手段である。
全てのGCN-GPUではウェーブフロントは64スレッドで構成され、全てのNVIDIA GPUではwarpは32スレッドで構成される。
AMDの解決策は、複数のウェーブフロントを各SIMD-VUに割り振ることである。ハードウェアはレジスタを異なるウェーブフロントに振り分けて、メモリにある一つのウェーブフロントが何らかの結果を待機している時、CUスケジューラはSIMD-VUに他のウェーブフロントを実行させる。ウェーブフロントはSIMD-VU毎に割り振られており、SIMD-VUはウェーブフロントを入れ替えない。最大10個のウェーブフロントが1基のSIMD-VUに割り振られる。(従ってCUあたり40個。)
CodeXLでは、SGPRおよびVGPRの数と波紋の数の関係を表にしているが、基本的にSGPRSの場合はmin(104, 512/numwavefronts)、VGPRSの場合は256/numwavefrontsとなる。
ストリーミングSIMD拡張命令に関連して、この最も基本的な並列度の概念は、しばしば「ベクトル幅」と呼ばれることに注意されたい。ベクトル幅は、その中の総ビット数によって特徴付けられる。
SIMDベクタユニット
編集各SIMDベクタユニットは
- 16レーンの整数型および浮動小数点ベクタのALU
- 64KiBベクタ汎用レジスタ
- 48ビットプログラムカウンタ
- 10個のウェーブフロント用命令バッファ
- ウェーブフロントは64スレッドのグループで、一つの論理VGPRのサイズである。
- 64スレッドウェーブフロントは4サイクルで16レーンSIMDユニットに渡される。
各SIMD-VUは10個のウェーブフロント命令バッファを持ち、1つのウェーブフロントの実行に4サイクルを要する。
オーディオおよびビデオアクセラレーションSIPブロック
編集追加のASICブロックにおける最も大きな違いは このようなASICブロック(Unified Video Decoder、Video Coding Engine、AMD TrueAudioなど)はGCNマイクロアーキテクチャまたはGCN命令セットのいずれとも働きかけない。これらはGCNのイテレーションを実装しているすべての、またはほとんどのチップにある単純なASICブロックである。この項目はGCN命令セットおよびマイクロアーキテクチャを文書化しているものと思われるが、ASICブロックについての情報を見つけるのはやや困難である。
統合型仮想メモリ (Unified virtual memory)
編集AnandTechは2011年の解説で、Graphics Core Nextでサポートされる統合型仮想メモリ (unified virtual memory) について説明している[7]。
-
 旧来のPCI Express越しにグラフィックスカードが存在するデスクトップコンピュータアーキテクチャ。CPUとGPUは異なるアドレス空間で物理メモリが隔離されている。すべてのデータはPCIeバスを通してコピーする必要がある。注:図は帯域幅を示しており、メモリレイテンシではない。
旧来のPCI Express越しにグラフィックスカードが存在するデスクトップコンピュータアーキテクチャ。CPUとGPUは異なるアドレス空間で物理メモリが隔離されている。すべてのデータはPCIeバスを通してコピーする必要がある。注:図は帯域幅を示しており、メモリレイテンシではない。 -
 GCNでは「統合型仮想メモリ」をサポートする。ゼロコピー、すなわちデータの代わりにポインタのみがコピーされる。これがHSAの最大の特徴である。
GCNでは「統合型仮想メモリ」をサポートする。ゼロコピー、すなわちデータの代わりにポインタのみがコピーされる。これがHSAの最大の特徴である。 -
 統合型グラフィックス(およびTeraScaleグラフィックスのAMD APU)は区画されたメインメモリの制約を受ける。システムメモリの一部がGPUに排他的に割り当てられ、ゼロコピーは不可能で、データはシステムメモリバスを通してもう一方の区画にコピーされる。
統合型グラフィックス(およびTeraScaleグラフィックスのAMD APU)は区画されたメインメモリの制約を受ける。システムメモリの一部がGPUに排他的に割り当てられ、ゼロコピーは不可能で、データはシステムメモリバスを通してもう一方の区画にコピーされる。 -
![GCNグラフィックスのAMD APUは統合型メインメモリにより不足がちな帯域幅を効率よく使用することができる。[8]](//up.wiki.x.io/wikipedia/commons/thumb/3/36/HSA-enabled_integrated_graphics_ja.png/320px-HSA-enabled_integrated_graphics_ja.png) GCNグラフィックスのAMD APUは統合型メインメモリにより不足がちな帯域幅を効率よく使用することができる。[8]
GCNグラフィックスのAMD APUは統合型メインメモリにより不足がちな帯域幅を効率よく使用することができる。[8]



![GCNグラフィックスのAMD APUは統合型メインメモリにより不足がちな帯域幅を効率よく使用することができる。[8]](/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:HSA-enabled_integrated_graphics_ja.png)
ヘテロジニアスシステムアーキテクチャ (HSA)
編集
ハードウェアに実装されているいくつかのHSA固有機能はオペレーティングシステムのカーネルおよび特定のデバイスドライバのサポートを必要とする。例えば、2014年7月にAMDは安定版Linuxカーネル 3.17用にGraphics Core NextベースのRadeonグラフィックスカードをサポートする83個のパッチを公開した。このドライバは "HSAカーネルドライバ" と名付けられ、DRMグラフィックスデバイスドライバが/drivers/gpu/drm[10]に配置されたように/driver/gpu/hsaに配置され、Radeonカード用のDRMドライバを改良したものであった[11]。この初期の実装は "Kaveri" APUまたは "Berlin" APU への対応に重点を置き、すでにあるRadeonカーネルグラフィックスドライバ (kgd) との組み合わせで動作した。
ハードウェアスケジューラ
編集これらはスケジューリングを行うために使用され[12]、 少なくとも1つのACEにおいて少なくとも1つの空のキューが存在するまでバッファリングすることによって、ドライバからハードウェアへのACEへのコンピュートキューの割り当てをオフロードし、HWSは、すべてのキューが満杯になるか、安全に割り当てられるキューがなくなるまで、バッファリングされたキューを直ちにACEに割り当てる[13]。スケジューリング作業の一部には、優先順位の高いキューが含まれている。これは、重要なタスクを他のタスクよりも高い優先順位で実行できるようにするもので、優先順位の低いタスクが優先順位の高いタスクを実行するためにプリエンプションされる必要はない。したがって、優先順位の高いタスクが使用していないリソースを他のタスクに使用させながら、GPUをできるだけ占有するようにスケジュールされた優先順位の高いタスクとタスクを同時に実行することができる[12]。 これらは本質的にディスパッチ・コントローラーを持たない非同期型コンピュート・エンジンである[12]。第4世代GCNマイクロアーキテクチャーで初めて導入されたが[12]、第3世代GCNマイクロアーキテクチャーにも内部テストのために存在していた[14]。ドライバーのアップデートにより、第3世代GCNパーツのハードウェア・スケジューラーが製品として使用できるようになった[12]。
プリミティブ破棄アクセラレータ
編集このユニットは縮退トライアングルがバーテックスシェーダーを通過し、さらにどのフラグメントもカバーしないトライアングルがフラグメントシェーダーを通過する前に、それを破棄する[15]。このユニットは第4世代GCNマイクロアーキテクチャで追加された[15]。
世代
編集初代GCN
編集| 発売日 | 2012年1月 |
|---|---|
| 歴史 | |
| 前身 | TeraScale 3 |
| 後継 | 第2世代GCN |
Southern Islands系GPU、Radeon HD 7000/HD 8000/Rx 200/Rx 300/Rx 400シリーズでサポート。
- CPUおよびGPUの統合型アドレス空間で64ビットアドレス割り当て(x86-64アドレス空間)をサポート[7]
- Partially Resident Texturesをサポート[17]、DirectXおよびOpenGL拡張機能によって仮想メモリのサポートが有効になる
- AMD PowerTuneサポート、特定のTDPの範囲内で動的にパフォーマンスを調整する[18]
- Mantle (API)をサポート
Graphics Core Nextマイクロアーキテクチャは4基のTMUと1基のROPからなる64基のシェーダープロセッサをコンピュートユニット (CU) に統合している。計算処理およびディスパッチを制御する非同期コンピュートエンジン (Asynchronous Compute Engine; ACE) がある。[19][20]
ZeroCore Power
編集ZeroCore Powerは長期無負荷省電力技術である[21]。AMD ZeroCore Power技術はAMD PowerTuneに付随する。
チップ
編集単体GPU: (Southern Islands系)
- Oland
- Cape Verde
- Pitcairn
- Tahiti
第2世代GCN
編集| 発売日 | 2013年2月 |
|---|---|
| 歴史 | |
| 前身 | 初代GCN |
| 後継 | 第3世代GCN |

第2世代GCNはRadeon HD 7790とともに追加され、Radeon HD 8770, Rx 260/260X, Rx 290/290X, R9 295X2, Rx 360, Rx 390/390X, Rx 455、またSteamrollerベースのデスクトップ向けKaveri APU、モバイル向けKaveri APU、PumaベースのBeemaおよびMullins APUにも適用されている。これはAMD TrueAudioやAMD PowerTune技術の改良版といった最初のGCNを上回るいくつかの有利な点を備えている。
第2世代GCNではシェーダーエンジン (SE) と呼ばれる機構を追加している。シェーダーエンジンは1基のジオメトリプロセッサ、最大11基のCU (Hawaiiチップ)、ラスタライザ、ROPおよびL1キャッシュから構成される。シェーダーエンジンに含まれないのものにGraphics Command Processor、8基のACE、L2キャッシュおよびメモリコントローラ、またオーディオおよびビデオアクセラレータ、ディスプレイコントローラ、2基のDMAコントローラとPCIeインターフェースがある。
A10-7850K "Kaveri"は8基のCU、および非依存スケジュールとアイテムのディスパッチ用に8基のACEを搭載している[22]。
2013年11月にAMD Developer Summitでマイケル・メンターはRadeon R9 290Xのプレゼンテーションを行った[23]。
チップ
編集単体GPU(Sea Islands系):
- Bonaire
- Hawaii
APU:
- Temash
- Kabini
- Liverpool
- Durango
- Kaveri
- Godavari
- Mullins
- Beema
- Carrizo-L
第3世代GCN
編集| 発売日 | 2015年6月 |
|---|---|
| 歴史 | |
| 前身 | 第2世代GCN |
| 後継 | 第4世代GCN |
第3世代GCN[24]は2014年にTonga GPUを搭載するRadeon R9 285およびR9 M295Xとともに紹介された。注目点はテッセレーションパフォーマンスの改善、メモリ帯域幅の使用を抑制するためのデルタ色可逆圧縮、改良されてより効率的になった命令セット、新しい高品質ビデオスケーラ、および新しいマルチメディアエンジン(ビデオエンコーダ・デコーダ)である。デルタ色圧縮はMesaでサポートされた[25]。
チップ
編集単体GPU:
- Tonga (Volcanic Islands family), comes with UVD 5.0
- Fiji (Pirate Islands family), comes with UVD 6.0 and High Bandwidth Memory (HBM 1)
APU:
第4世代GCN
編集| 発売日 | 2016年6月 |
|---|---|
| 歴史 | |
| 前身 | 第3世代GCN |
| 後継 | 第5世代GCN |
Arctic Islands系GPUは、2016年の第2四半期にAMD Radeon 400シリーズとして登場した。3Dエンジン(=GCA(Graphics and Compute array)またはGFX)はTongaチップに搭載されているものと同じであるが[27]、Polarisはより新しいDisplay Controllerエンジン、UVDバージョン6.3などを搭載している。
Polaris 30以外のすべてのPolarisベースのチップは、サムスン電子が開発し、GlobalFoundriesにライセンスされた14nm FinFETプロセスで製造されている[28]。Polaris 30は、サムスンとGlobalFoundriesが開発した12nm LP FinFETプロセスノードで製造されている。第4世代GCN命令セットアーキテクチャは、第3世代GCNと互換性があり、14nm FinFETプロセスへの最適化により、第3世代GCNよりも高いGPUクロックを実現している[29]。アーキテクチャの改善には、新しいハードウェアスケジューラ、新しいプリミティブディスカードアクセラレータ、新しいディスプレイコントローラ、4K解像度のHEVCを毎秒60フレームかつ、各カラーチャンネル10ビットでデコード可能な最新のUVDなどが含まれる。
チップ
編集単体GPU[30]:
- Polaris 10 (Ellesmere)
- Radeon RX 470, 480
- Polaris 11 (Baffin)
- Radeon RX 460, 560
- Polaris 12 (Lexa)
- Radeon RX 540, 550
- Polaris 20 (14nm LPPで製造し、Polaris 10のクロックを上げたもの)
- Radeon RX 570, 580
- Polaris 21 (14nm LPPで製造し、Polaris 11のクロックを上げたもの)
- Radeon RX 560
- Polaris 22
- Radeon RX Vega M GH, M GL
- Polaris 30 (12nm LPPで製造し、Polaris 20のクロックを上げたもの)
- Radeon RX 590
演算性能
編集全てのGCN第4世代GPUのFP64性能は、FP32性能の1/16である。
第5世代GCN
編集| 発売日 | 2017年6月 |
|---|---|
| 歴史 | |
| 前身 | 第4世代GCN |
| 後継 | RDNA1 |
2017年1月、AMDは「Next-Generation Compute Unit」と呼ばれる次世代GCNアーキテクチャーの詳細を明らかにした[29][31][32]。新しい設計により、クロックあたりの命令数の増加、クロック速度の向上、HBM2のサポート、より大きなメモリアドレス空間が期待されていた。ディスクリート・グラフィックス・チップセットには「HBCC(High Bandwidth Cache Controller)」が搭載されているが、APUには搭載されていない[33]。さらに、新しいチップには、ラスタライズとレンダーの出力ユニットの改良が期待されていた。ストリームプロセッサーは前世代から大幅に変更され、8ビット、16ビット、32ビットの数値に対するRapid Packed Mathテクノロジーをサポートしている。これにより、低い精度が許容される場合には、性能面で大きなアドバンテージが得られる(2つの半精度の数値を1つの単精度の数値と同じレートで処理する場合など)。
NvidiaはMaxwellでタイルベースのラスタライズとビニングを導入し[34]、これがMaxwellの効率向上の大きな要因となった。AnandTechは、Vegaで導入される新しい「DSBR(Draw Stream Binning Rasterizer)」により、エネルギー効率の最適化に関してVegaがようやくNvidiaに追いつくと想定した[35]。
また、新しいシェーダーステージである「プリミティブシェーダー」のサポートも追加された[36]。プリミティブシェーダーは、より柔軟なジオメトリ処理を実現し、レンダリングパイプラインのバーテックスシェーダーとジオメトリシェーダーを置き換える。
チップ
編集単体GPU:
- Vega 10
- Radeon RX Vega 64, 56
- Vega 12
- Vega 20
- Radeon VII
APU: Raven Ridge[37]には、VCEおよびUVDに代わるVCN 1が搭載され、VP9のハードウェアデコードが可能になった。
演算性能
編集Vega 20を除くすべてのGCN第5世代GPUの倍精度浮動小数点(FP64)性能は、FP32性能の1/16である。Vega 20ではFP32の1/2となっている[38]。すべてのGCN第5世代GPUは、FP32の2倍の性能を持つ半精度浮動小数点(FP16)計算をサポートしている。
脚注
編集- ^ "AMD Launches World's Fastest Single-GPU Graphics Card – the AMD Radeon HD 7970" (Press release). AMD. 22 December 2011. 2015年1月20日閲覧。
- ^ “Feature matrix of the free and open-source "Radeon" graphics device driver”. 2014年7月9日閲覧。
- ^ “LLVM back-end amdgpu”. 2015年9月7日閲覧。
- ^ “AMD Boltzmann Initiative – Heterogeneous-compute Interface for Portability (HIP)” (2015年11月16日). 2016年1月15日閲覧。
- ^ DirectX 12 Async Shaders An Advantage For AMD And An Achilles Heel For Nvidia Explains Oxide Games Dev
- ^ AMD Simplified: Asynchronous Shaders - YouTube
- ^ a b “Not Just A New Architecture, But New Features Too”. AnandTech (2011年12月21日). 2014年7月11日閲覧。
- ^ “Kaveri microarchitecture”. SemiAccurate (2014年1月15日). 2014年7月11日閲覧。
- ^ Dave Airlie (2014年11月26日). “Merge AMDKFD”. freedesktop.org. 2015年1月21日閲覧。
- ^ “/drivers/gpu/drm”. kernel.org. 2014年7月11日閲覧。
- ^ “[PATCH 00/83 AMD HSA kernel driver]”. LKML (2014年7月10日). 2014年7月11日閲覧。
- ^ a b c d e Angelini, Chris (June 29, 2016). “AMD Radeon RX 480 8GB Review”. Tom's Hardware: p. 1 August 11, 2016閲覧。
- ^ “Dissecting the Polaris Architecture” (2016年). August 12, 2016閲覧。
- ^ Shrout, Ryan (June 29, 2016). “The AMD Radeon RX 480 Review - The Polaris Promise”. PC Perspective: p. 2 August 12, 2016閲覧。
- ^ a b Smith, Ryan (June 29, 2016). “The AMD Radeon RX 480 Preview: Polaris Makes Its Mainstream Mark”. AnandTech: p. 3 August 11, 2016閲覧。
- ^ “AMD Radeon HD 7000 Series to be PCI-Express 3.0 Compliant”. TechPowerUp. July 21, 2011閲覧。
- ^ “AMD Details Next Gen. GPU Architecture”. August 3, 2011閲覧。
- ^ Tony Chen, Jason Greaves, “AMD's Graphics Core Next (GCN) Architecture”, AMD 2016年8月13日閲覧。
- ^ “AMD Graphics Core Next” (pdf). AMD. p. 40 (2011年6月15日). 2014年7月15日閲覧。 “Asynchronous Compute Engine (ACE)”
- ^ “AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute”. AnandTech (2011年12月21日). 2014年7月15日閲覧。 “AMD's new Asynchronous Compute Engines serve as the command processors for compute operations on GCN. The principal purpose of ACEs will be to accept work and to dispatch it off to the CUs for processing.”
- ^ “Managing Idle Power: Introducing ZeroCore Power”. AnandTech (2011年12月22日). 2015年4月29日閲覧。
- ^ “AMD's Kaveri A10-7850K tested”. AnandTech (2014年1月14日). 2014年7月7日閲覧。
- ^ “AMD Radeon R9-290X” (2013年11月21日). 2014年7月18日閲覧。
- ^ http://images.anandtech.com/doci/9319/Slide%2019%20-%20GCN%20Overview.png
- ^ “Add DCC Support”. Freedesktop.org (2015年10月11日). 2015年10月14日閲覧。
- ^ a b Cutress, Ian (1 June 2016). “AMD Announces 7th Generation APU”. Anandtech.com 1 June 2016閲覧。
- ^ “Radeon Feature Matrix: GCA”. 2021年7月16日閲覧。
- ^ “Radeon Technologies Group – January 2016 – AMD Polaris Architecture”. Guru3d.com (2016年1月4日). 2021年7月16日閲覧。
- ^ a b Smith, Ryan (2017年1月5日). “The AMD Vega Architecture Teaser: Higher IPC, Tiling, & More, coming in H1'2017” 2017年1月10日閲覧。
- ^ WhyCry (24 March 2016). “AMD confirms Polaris 10 is Ellesmere and Polaris 11 is Baffin”. VideoCardz. 8 April 2016閲覧。
- ^ Kampman, Jeff (January 5, 2017). “The curtain comes up on AMD's Vega architecture” January 10, 2017閲覧。
- ^ Shrout, Ryan (January 5, 2017). “AMD Vega GPU Architecture Preview: Redesigned Memory Architecture”. PC Perspective January 10, 2017閲覧。
- ^ Kampman, Jeff (2017年10月27日). “AMD's Ryzen 7 2700U and Ryzen 5 2500U APUs revealed” 2017年10月27日閲覧。
- ^ Raevenlord (2017年3月1日). “On NVIDIA's Tile-Based Rendering”. techPowerUp. 2021年7月16日閲覧。
- ^ “Vega Teaser: Draw Stream Binning Rasterizer”. Anandtech.com (2017年1月5日). 2021年7月16日閲覧。
- ^ “The curtain comes up on AMD's Vega architecture”. Techreport.com (2017年1月5日). 2021年7月16日閲覧。
- ^ Ferreira, Bruno (May 16, 2017). “Ryzen Mobile APUs are coming to a laptop near you”. Tech Report May 16, 2017閲覧。
- ^ "AMD Unveils World's First 7nm Datacenter GPUs – Powering the Next Era of Artificial Intelligence, Cloud Computing and High Performance Computing (HPC) | AMD". AMD.com (Press release). 6 November 2018. 2018年11月10日閲覧。
{kind=link}